Gemini: o que é e como usá-lo corretamente para obter o máximo proveito.
Gemini é a plataforma de IA do Google que processa e gera linguagem natural, simplificando seu trabalho diário.

A OpenAI chegou primeiro com o ChatGPT e revolucionou o mundo. Mas o Google passou 25 anos construindo o mecanismo de busca mais poderoso da história, tem acesso a mais dados do que qualquer outra empresa, controla o sistema operacional de 3 bilhões de celulares e acaba de lançar o modelo de inteligência artificial mais ambicioso que já criou.
Chama-se Gemini. E se você ainda não o está usando, provavelmente está tomando decisões com menos informações do que poderia ter.
O Google Gemini não é apenas mais um chatbot que responde a perguntas. É uma família de modelos de inteligência artificial, um assistente digital e, ao mesmo tempo, uma tecnologia integrada a serviços como Android, Gmail, Google Drive, Docs, Maps, YouTube e outras ferramentas do ecossistema do Google.
O Gemini é usado para conversação, pesquisa, escrita, resumo de documentos, análise de imagens, revisão de código, organização de informações e execução de tarefas relacionadas a aplicativos do Google. Sua principal diferença em relação ao GPT reside não apenas em qual deles apresenta melhor desempenho, mas também na forma como cada tecnologia se integra às ferramentas que usamos diariamente.
Gemini pertence ao Google. GPT pertence à OpenAI. Gemini se destaca por sua relação direta com o ecossistema do Google, enquanto GPT é a família de modelos que alimenta o ChatGPT e vários aplicativos criados usando a API da OpenAI.
No entanto, afirmar que um é sempre melhor que o outro seria enganoso. A escolha certa depende do que você precisa fazer.
Para quem trabalha constantemente com Gmail, Google Drive, Docs, Agenda, Android ou Maps, o Gemini pode ser especialmente útil. Para quem busca um assistente de conversação geral, agendamento avançado, criação de projetos, análise de arquivos ou fluxos de trabalho personalizados, o ChatGPT também pode ser uma alternativa muito poderosa.
A melhor maneira de decidir não é perguntar qual obtém a pontuação mais alta em um único teste. O que importa é comparar qual resolve melhor a sua tarefa real, com menos correções, menos etapas e resultados mais confiáveis.
O que é Gêmeos?
Gemini é o modelo de inteligência artificial generativa do Google, multimodal desde sua concepção básica. Ele pode processar e gerar texto, imagens, áudio, vídeo e código em uma única conversa, com acesso à internet em tempo real.
Gemini é o nome que o Google usa para identificar uma família de modelos de inteligência artificial generativa e os produtos desenvolvidos com base neles.
Essa distinção é importante porque o Gemini não é um aplicativo isolado com uma única funcionalidade. É um ecossistema completo de inteligência artificial.
Em sua forma mais simples, o Gemini funciona como um assistente de conversação. Você digita uma pergunta, anexa um arquivo ou fala usando sua voz, e o sistema gera uma resposta.
Em aplicações mais avançadas, é possível analisar documentos extensos, comparar informações, examinar uma fotografia, interpretar código, consultar serviços conectados, preparar um relatório ou ajudar a automatizar processos por meio de uma API.
Preço Gemini
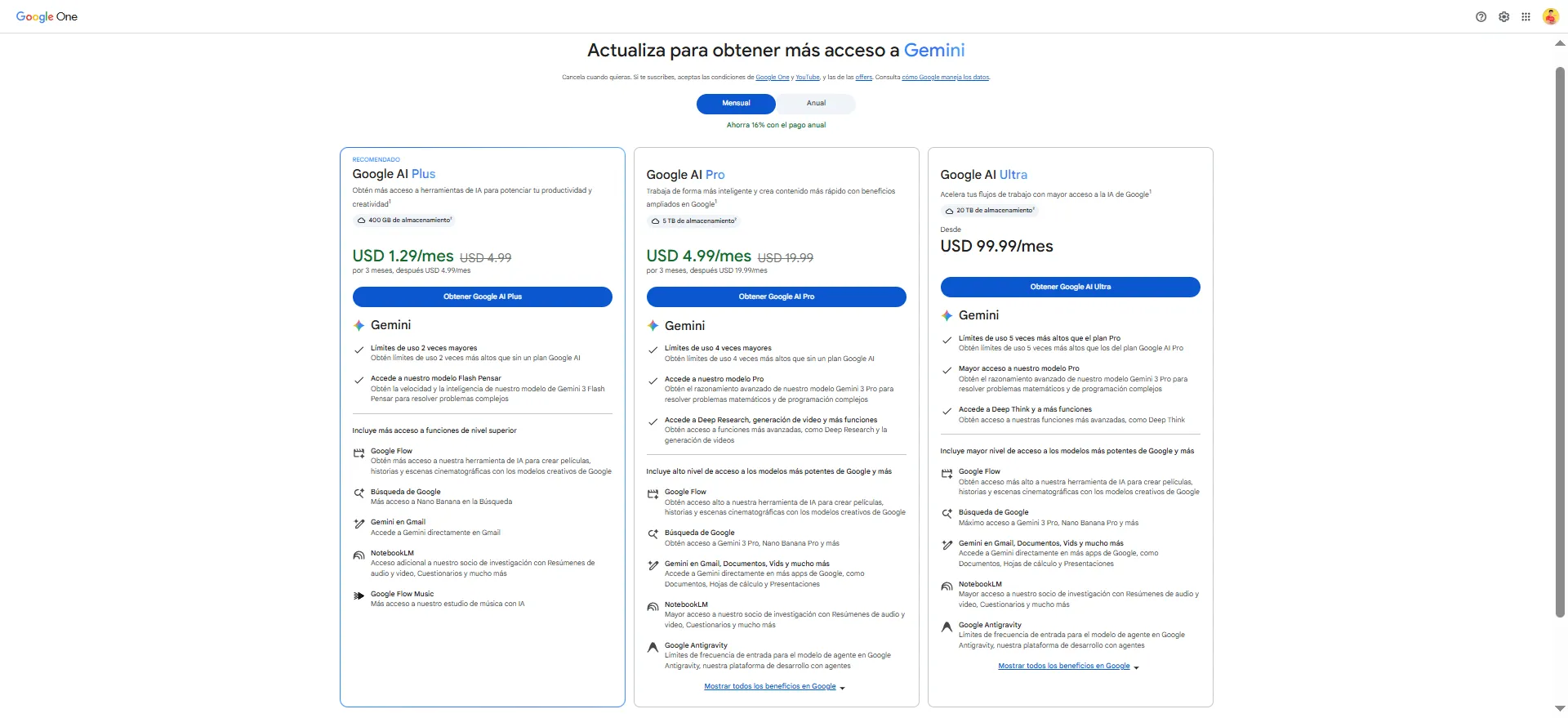
A Gemini também oferece um plano gratuito: acesso em gemini.google.com com o modelo Gemini 3 Flash.
- Google AI Plus: US$ 1,29 por mês.
- Google AI Pro: US$ 4,99 por mês.
- Google AI Ultra: US$ 99,99 por mês.
O que significa inteligência artificial generativa?
A inteligência artificial generativa é um tipo de tecnologia capaz de produzir conteúdo novo a partir de instruções. Esse conteúdo pode incluir:
- Textos.
- Resumos.
- E-mails.
- Imagens.
- Código de programação.
- Tabelas.
- Ideias.
- Planos.
- Explicações.
- Roteiros.
- Informação.
- Conteúdo de áudio ou multimídia, dependendo do modelo utilizado.
A palavra "generativo" não significa que a inteligência artificial pensa exatamente como uma pessoa. Significa que ela pode gerar uma resposta calculando qual conteúdo é mais apropriado com base na solicitação, no contexto disponível e nos padrões aprendidos durante seu treinamento.
Por essa razão, um geminiano pode escrever uma explicação convincente e ainda assim estar errado. Sua capacidade de escrever com segurança não garante que todos os fatos sejam verdadeiros.
A inteligência artificial deve ser usada como uma ferramenta de apoio, não como uma fonte infalível.
Como funciona o Gemini
O funcionamento interno exato do Gemini contém elementos proprietários que não são de domínio público. No entanto, é possível compreender seu processo geral sem se aprofundar em explicações excessivamente técnicas.
Quando uma pessoa digita uma instrução, o Gemini executa várias etapas. Primeiro, ele interpreta a entrada. Essa entrada pode ser texto, uma imagem, áudio, vídeo, um arquivo ou uma combinação de diferentes formatos.
Em seguida, divide a informação em unidades que o modelo pode processar. No caso de texto, essas unidades são geralmente chamadas de tokens. Um token pode representar uma palavra, parte de uma palavra, um símbolo ou uma combinação de caracteres.
Em seguida, o modelo analisa a relação entre essas unidades. Ele não busca apenas palavras exatas. Tenta compreender o contexto, a intenção, o formato solicitado, as instruções anteriores e os dados incluídos na conversa.
Em seguida, calcula uma resposta provável. Faz isso passo a passo, gerando fragmentos de conteúdo com base em padrões aprendidos e instruções recebidas.
Em certos casos, o Gemini também pode usar ferramentas externas. Por exemplo, ele pode recuperar informações atuais por meio de uma pesquisa, analisar um arquivo, executar código, usar dados do Google Maps ou interagir com um aplicativo conectado.
Por fim, apresenta o resultado ao usuário na forma de texto, tabela, código, imagem, relatório ou ação, dependendo da função utilizada.
O processo completo pode ser resumido da seguinte forma:
- O usuário envia uma instrução.
- Gêmeos identifica a intenção.
- Analise o contexto disponível.
- Decida se você precisa usar alguma ferramenta.
- Processar as informações.
- Gere uma resposta.
- Aplique filtros e controles de segurança.
- Mostre o resultado.
História de Gêmeos
A história do Gemini não começa em 2023. Ela começa muito antes, nos laboratórios do Google DeepMind e do Google Brain, dois dos centros de pesquisa em IA mais respeitados do mundo. Durante anos, o Google treinou modelos de linguagem como o LaMDA e o PaLM, mas todos eles tinham uma coisa em comum: eram ferramentas internas ou produtos secundários, nunca o produto principal.
O lançamento do ChatGPT em novembro de 2022 mudou isso drasticamente. O Google, que dominava as buscas há duas décadas, de repente se viu diante de uma ameaça direta ao seu negócio principal. A resposta foi o Bard, lançado às pressas em fevereiro de 2023, que não causou exatamente a melhor impressão. Em sua apresentação ao vivo, o Bard cometeu um erro factual que custou ao Google US$ 100 bilhões em valor de mercado em um único dia.
Mas esse revés acelerou algo que já estava em andamento. Em dezembro de 2023, o Google apresentou oficialmente o Gemini 1.0, o modelo construído do zero com a multimodalidade como recurso central — e não como uma ideia posterior. E em 2024 e 2025, a evolução foi rápida e decisiva.
Data de lançamento atualizada
- Dezembro de 2023 → Gemini 1.0 ·
- Fev. 2024 → Gemini 1.5 Pro (1 milhão de tokens) ·
- Dez de 2024 → Gemini 2.0 Flash ·
- Fev. 2025 → Gemini 2.5 Pro ·
- 2025 → Gemini 3 Flash como modelo padrão para todos os usuários
O que diferencia o Gemini de seus antecessores não é apenas o poder do modelo, mas a visão por trás dele: o Google não queria construir um chatbot. Queria construir um assistente universal que funcionasse em todos os produtos que as pessoas já usam — Gmail, Maps, YouTube, Android, Chrome — e que pudesse agir de forma inteligente em nome do usuário.
Arquitetura Transformer e o mecanismo de atenção
O Gemini é construído sobre a arquitetura Transformer, que tem sido o padrão da indústria para IA desde 2017. O que diferencia o Gemini é a forma como o Google otimizou essa arquitetura para lidar com janelas de contexto enormes: até 1 milhão de tokens nas versões mais avançadas.
Para você ter uma ideia, 1 milhão de tokens equivale aproximadamente a um romance de 700 páginas — ou 10 horas de transcrição de áudio, ou um repositório de código completo de tamanho médio.
O que é a janela de contexto?
É a quantidade de informações que o modelo consegue "manter na memória" simultaneamente durante uma conversa. Quanto maior o número, mais documentos, histórico e contexto ele consegue processar antes de começar a "esquecer" as informações anteriores. O Gemini 2.5 Pro possui atualmente a maior capacidade de armazenamento do mercado entre os modelos para o consumidor final.
Acesso à internet em tempo real
Ao contrário de modelos com data de corte de conhecimento, o Gemini está conectado ao Google Search por padrão. Quando você faz uma pergunta sobre algo atual — um evento recente, o preço de algo, as últimas notícias — ele pode pesquisar em tempo real e fornecer uma resposta atualizada. Essa é uma grande vantagem em relação às versões do ChatGPT que usam dados de treinamento desatualizados.
Pesquisa aprofundada: pesquisa autônoma em várias etapas
Uma das funcionalidades mais poderosas do Gemini em 2025 é a Pesquisa Profunda, disponível no plano Pro. Trata-se de um agente capaz de planejar pesquisas complexas, executar múltiplas buscas, sintetizar mais de 20 fontes e entregar um relatório estruturado. Tarefas que levariam de 3 a 4 horas de pesquisa manual, o Gemini realiza em minutos, com uma qualidade de síntese superior à da maioria das buscas manuais.
Por que se diz que Gêmeos é multimodal?
Gemini é descrita como uma inteligência artificial multimodal porque consegue trabalhar com diferentes tipos de informação.
Um sistema baseado apenas em texto só consegue interpretar palavras escritas. Um modelo multimodal pode relacionar texto, imagens, áudio, vídeo, documentos e código em uma mesma tarefa.
Por exemplo, você pode fotografar uma placa de circuito e pedir que ela identifique os componentes visíveis. Você também pode anexar um documento e solicitar um resumo, compartilhar uma captura de tela de um erro de programação ou exibir um gráfico para que ela explique seus dados.
A multimodalidade nos permite fazer perguntas como estas:
- Qual componente aparece queimado nesta placa?
- Resuma este PDF e extraia as datas importantes.
- Analise esta fotografia e descreva os objetos.
- Analise esta captura de tela e explique-me o erro.
- Compare as informações nessas duas imagens.
- Converta esses dados em uma tabela.
- Explique-me o que acontece neste vídeo.
- Analise este repositório e identifique quaisquer problemas potenciais.
A qualidade do resultado dependerá da clareza do arquivo, do modelo selecionado, do contexto fornecido e da complexidade da tarefa.